¶ Script Slurm de base
Nous allons ici exécuter une tâche simple d'une durée de 20 secondes. Chaque ligne commençant par #SBATCH donne des commandes à Slurm qui seront utilisées pour configurer votre tâche. Les lignes avec echo affichent simplement du texte et sleep 20 demande à la machine d'attendre 20 secondes avant de continuer.
Pour soumettre un script Slurm au nœud, vous devez exécuter sbatch hello_cluster.sh depuis votre terminal dans le répertoire où vous avez créé le script. Vous pouvez fournir des options supplémentaires à Slurm directement avec la commande sbatch (par exemple, vous pouvez donner le nom de la tâche sbatch --job-name=test_job hello_cluster.sh ; les options de la ligne de commande remplacent les options du script Slurm), mais nous ne l'aborderons pas ici.
Le script Slurm est un simple fichier texte. Créez un fichier (vous pouvez utiliser nano, vim ou tout autre éditeur de texte) nommé hello_cluster.sh et copiez les commandes suivantes dans ce fichier. Pour ce faire, vous pouvez utiliser Ctrl + Maj + V ou CMD + V pour Mac. Selon votre type d'accès, le script devra être légèrement modifié.
Pour vérifier les comptes de facturation auxquels vous avez accès, vous pouvez utiliser la commande suivante :
sacctmgr show user name=$USER withassoc format=User%30,Account%30,DefaultAccount%30
¶ CPU heures
Exemple de script de soumission. Vous devez adapter les paramètres de partition et de compte (account) en fonction de votre type d'accès : ondemand, dedicated ou test.
#!/bin/bash
#_______________________________________________________________________________
# INSTRUCTIONS POUR SLURM
#_______________________________________________________________________________
#SBATCH --job-name=HelloCluster # nom du travail - remplacez-le par un nom qui vous convient
#SBATCH --output=results_%x_%j.out # fichier de sortie - %x est le nom du travail, %j est l'ID du travail
#SBATCH --error=error_%x_%j.err # fichier d'erreurs - %x correspond au nom du travail et %j à son ID
#SBATCH --time=00:02:00 # durée maximale d'exécution du travail (HH:MM:SS) - ici 2 minutes
#SBATCH --nodes=1 # nombre de nœuds
#SBATCH --ntasks=1 # nombre de tâches (processus)
#SBATCH --cpus-per-task=1 # nombre de processeurs par tâche
#SBATCH --mem=50M # mémoire requise par tâche (ex : 50 Mo)
#SBATCH --partition=cpu-ondemand # partition - pour CPU à la demande
#SBATCH --account=ondemand@groupname # compte à créditer
#_________________________________Facultatif______________________________________
##SBATCH --mail-user=your.name@youremail.com # e-mail à utiliser pour la communication slurm
##SBATCH --mail-type=END # slurm enverra un e-mail lorsque le travail sera terminé
#_______________________________________________________________________________
# Commandes qui seront exécutées
#_______________________________________________________________________________
echo ' ------------------------------------------------------ '
echo ' Bonjour depuis le cluster ! '
echo " Cette tâche s'exécute sur le nœud : $(hostname) " # afficher le nom du nœud
echo " Lancée le : $(date) " # afficher la date de début de la tâche
echo "-------------------------------------------- -----------"
# Nous simulons une tâche de 20 secondes
echo " La tâche va maintenant s'exécuter pendant 20 secondes... "
sleep 20
echo " Tout est terminé. "
echo "-------------------------------------- ----------------"
echo " Tâche terminée le : $(date) "
echo " ------------------------------------------------------ "
¶ Ondemand user
En tant qu'utilisateur « ondemand », vous devez respecter un quota. Ce quota est exprimé en minutes et indique votre temps de calcul alloué :
slurm-quota stats $USER
Pour un utilisateur disposant d'un accès ondemand, vous devez spécifier la partition et le compte suivants :
#SBATCH --partition=cpu-ondemand # partition - pour CPU ondemand
#SBATCH --account=ondemand@groupname # compte à créditer
¶ Dedicated user
Pour un utilisateur disposant d'un accès dédié, vous devez spécifier une partition et un compte différents, mais le reste du script reste inchangé.
#SBATCH --partition=cpu-dedicated # partition - pour CPU dédié
#SBATCH --account=dedicated@groupname # compte à créditer
¶ Test user
En tant qu'utilisateur du CPU de test, vous disposez de 5 000 heures de CPU. Vous pouvez vérifier le quota dont vous disposez à l'aide de la commande suivante :
slurm-quota stats $USER
Pour un utilisateur disposant d'un accès test, vous devez spécifier un nom de compte spécial, mais le reste du script reste inchangé.
#SBATCH --partition=cpu-ondemand # partition - pour CPU ondemand
#SBATCH --account=ondemand@demo # compte à créditer
¶ GPU heures
Si vous avez accès à des heures GPU, vous devez légèrement adapter votre script Slurm. Le plus important est d'utiliser les ressources GPU, la partition et le compte corrects. Sur IO, vous pouvez avoir accès à trois options GPU qui peuvent être répertoriées avec sinfo -o "%N %G". Le résultat serait quelque chose comme ceci :
io-gpu-[01-03] gpu:nvidia_h100_80gb_hbm3:2(S:0),gpu:nvidia_h100_80gb_hbm3_4g.40gb:2(S:0), gpu:nvidia_h100_80gb_hbm3_1g.10gb:6(S:0)
Vous pouvez choisir d'utiliser le nombre de GPU H100 complet avec 80 Go de RAM comme suit
#SBATCH --gres=gpu:nvidia_h100_80gb_hbm3:%N
Par exemple, pour utiliser 2 cartes GPU H100 complètes, vous remplacerez %N par 2 :
#SBATCH --gres=gpu:nvidia_h100_80gb_hbm3:2
Pour utiliser la moitié de la carte, vous utiliseriez
#SBATCH --gres=gpu:nvidia_h100_80gb_hbm3_4g.40gb:%N
Et pour utiliser 1/8 de la carte, vous utiliseriez
#SBATCH --gres=gpu:nvidia_h100_80gb_hbm3_1g.10gb:%N
Votre consommation de quota (pour les utilisateurs à la demande et les utilisateurs test) dépendra de votre choix de carte GPU. Par exemple, utiliser la moitié d'une carte GPU pendant 24 heures sera moins coûteux que d'utiliser la totalité de la carte GPU pendant 24 heures. Vous devez garder à l'esprit les ressources nécessaires à votre cas spécifique.
Pour notre exemple de script, nous utiliserons 1/8 de la carte GPU avec 10 Go de RAM.
¶ Ondemand user
En tant qu'utilisateur « ondemand », vous devez respecter un quota. Ce quota est exprimé en minutes et indique votre temps de calcul alloué :
slurm-quota stats $USER
#!/bin/bash
#_______________________________________________________________________________
# INSTRUCTIONS POUR SLURM
#_______________________________________________________________________________
#SBATCH --job-name=HelloClusterGPU # nom du travail - remplacez-le par un nom qui vous convient
#SBATCH --output=results_%x_%j.out # fichier de sortie - %x est le nom du travail, %j est l'ID du travail
#SBATCH --error=error_%x_%j.err # fichier d'erreurs - %x correspond au nom du travail et %j à son ID
#SBATCH --time=00:02:00 # durée maximale d'exécution du travail (HH:MM:SS) - ici 2 minutes
#SBATCH --nodes=1 # nombre de nœuds
#SBATCH --ntasks=1 # nombre de tâches (processus)
#SBATCH --cpus-per-task=1 # nombre de processeurs par tâche
#SBATCH --mem=50M # mémoire requise par tâche (ex : 50 Mo)
#SBATCH --partition=gpu-ondemand # partition - pour CPU à la demande
#SBATCH --account=ondemand@groupname # compte à créditer - vérifier avec slurm-quota stats $USER
#SBATCH --gres=gpu:nvidia_h100_80gb_hbm3_1g.10gb:1 # type et nombre de GPUs
#_________________________________Facultatif______________________________________
##SBATCH --mail-user=your.name@youremail.com # e-mail à utiliser pour la communication slurm
##SBATCH --mail-type=END # slurm enverra un e-mail lorsque le travail sera terminé
#_______________________________________________________________________________
# Commandes qui seront exécutées
#_______________________________________________________________________________
echo ' ------------------------------------------------------ '
echo ' Bonjour depuis le cluster ! '
echo " Cette tâche s'exécute sur le nœud : $(hostname) " # afficher le nom du nœud
echo " GPU alloués : $SLURM_JOB_GPUS"
nvidia-smi --query-gpu=index,name
echo " Lancée le : $(date) " # afficher la date de début de la tâche
echo "-------------------------------------------- -----------"
# Nous simulons une tâche de 20 secondes
echo " La tâche va maintenant s'exécuter pendant 20 secondes... "
sleep 20
echo " Tout est terminé. "
echo "-------------------------------------- ----------------"
echo " Tâche terminée le : $(date) "
echo " ------------------------------------------------------ "
¶ Dedicated user
Pour un utilisateur disposant d'un accès dédié, vous devez spécifier une partition et un compte différents, mais le reste du script reste inchangé.
#SBATCH --partition=gpu-dedicated # partition - for GPU dédié
#SBATCH --account=dedicated@groupname # account to credit - check with slurm-quota stats $USER
¶ Test user
En tant qu'utilisateur du GPU de test, vous disposez de 1 000 heures de CPU et 24 1/2 carte GPU. Vous pouvez vérifier le quota dont vous disposez à l'aide de la commande suivante :
slurm-quota stats $USER
Pour un utilisateur disposant d'un accès test, vous devez spécifier un nom de compte spécial, mais le reste du script reste inchangé.
#SBATCH --account=ondemand-gpu@demo # account to credit - check with slurm-quota stats $USER
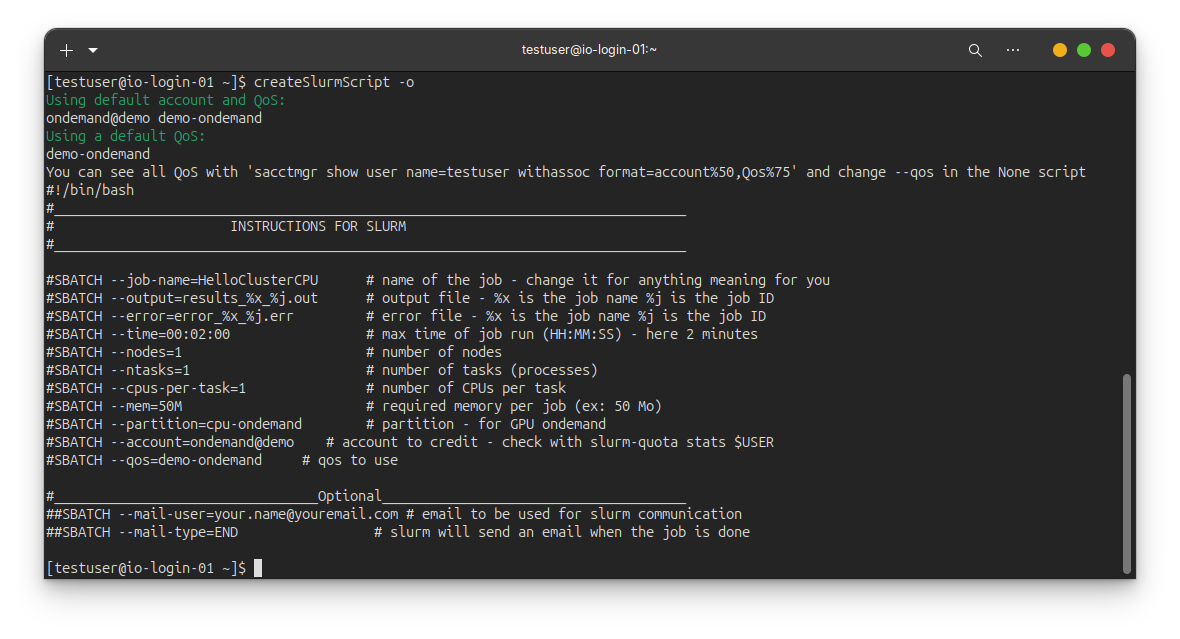
¶ Creation du script automatique
Utilisez notre outil pour créer votre script Slurm.
- Chargez le module :
module load io-local slurm-user-tools - Utilisez
createSlurmScript -opour créer votre script Slurm avec vos options par défaut
Utilisez createSlurmScript -h pour afficher toutes les options disponibles.
Exemple d'utilisation
¶ Vous avez besoin d'un module spécifique
Pour appeler des modules dans votre script Slurm, vous devez procéder de la même manière que sur le nœud de connexion. Avant d'exécuter toute commande et après toutes les commandes #SBATCH, vous devez ajouter :
#_______________________________________________________________________________
# Commandes qui seront exécutées
#_______________________________________________________________________________
module purge # supprimer tous les modules précédemment chargés
module load bioinfo-ifb python/3.9 # exemple : chargement du module Python
python3 my_script.py # vous pouvez désormais exécuter des scripts Python3